Overall summary:
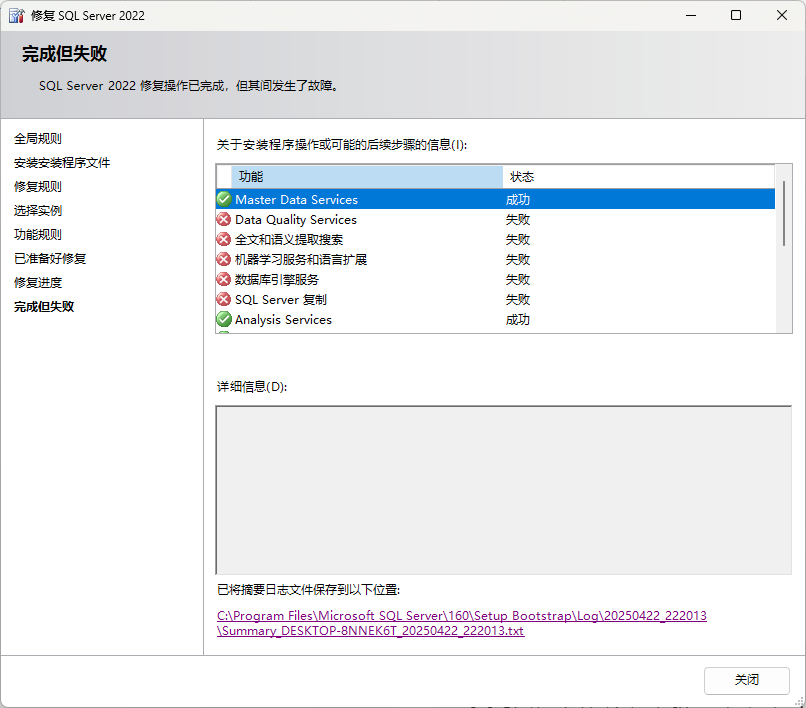
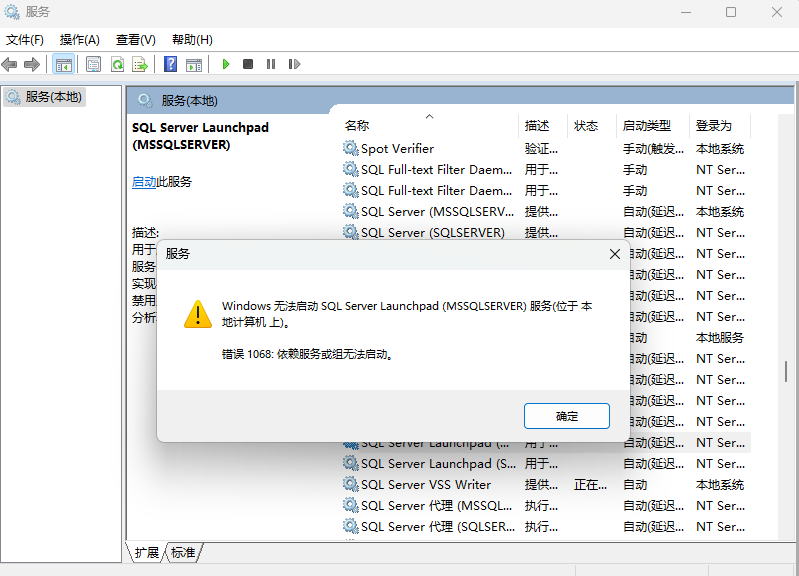
Final result: 失败: 请查看下面的详细信息
Exit code (Decimal): -2068578302
Start time: 2025-04-22 22:37:34
End time: 2025-04-22 22:45:18
Requested action: Repair
Setup completed with required actions for features.
Troubleshooting information for those features:
Next step for DQ: 使用以下信息解决错误,然后再次尝试运行安装过程。
Next step for FullText: 使用以下信息解决错误,然后再次尝试运行安装过程。
Next step for AdvancedAnalytics: 使用以下信息解决错误,然后再次尝试运行安装过程。
Next step for SQLEngine: 使用以下信息解决错误,然后再次尝试运行安装过程。
Next step for Replication: 使用以下信息解决错误,然后再次尝试运行安装过程。
Machine Properties:
Machine name: DESKTOP-8NNEK6T
Machine processor count: 12
OS version: Microsoft Windows 11 专业工作站版 (10.0.26100)
OS service pack:
OS region: 中国
OS language: 中文(中国)
OS architecture: x64
Process architecture: 64 位
OS clustered: 否
Product features discovered:
Product Instance Instance ID Feature Language Edition Version Clustered Configured
SQL Server 2022 MSSQLSERVER MSSQL16.MSSQLSERVER 数据库引擎服务 1033 Developer Edition 16.0.1000.6 否 是
SQL Server 2022 MSSQLSERVER MSSQL16.MSSQLSERVER 数据库引擎服务 2052 Developer Edition 16.0.1000.6 否 是
SQL Server 2022 MSSQLSERVER MSSQL16.MSSQLSERVER SQL Server 复制 1033 Developer Edition 16.0.1000.6 否 是
SQL Server 2022 MSSQLSERVER MSSQL16.MSSQLSERVER SQL Server 复制 2052 Developer Edition 16.0.1000.6 否 是
SQL Server 2022 MSSQLSERVER MSSQL16.MSSQLSERVER 全文和语义提取搜索 1033 Developer Edition 16.0.1000.6 否 是
SQL Server 2022 MSSQLSERVER MSSQL16.MSSQLSERVER Data Quality Services 1033 Developer Edition 16.0.1000.6 否 是
SQL Server 2022 MSSQLSERVER MSSQL16.MSSQLSERVER Data Quality Services 2052 Developer Edition 16.0.1000.6 否 是
SQL Server 2022 MSSQLSERVER MSSQL16.MSSQLSERVER 机器学习服务和语言扩展 1033 Developer Edition 16.0.1000.6 否 是
SQL Server 2022 MSSQLSERVER MSAS16.MSSQLSERVER Analysis Services 1033 Developer Edition 16.0.1000.6 否 是
SQL Server 2022 MSSQLSERVER MSAS16.MSSQLSERVER Analysis Services 2052 Developer Edition 16.0.1000.6 否 是
SQL Server 2022 SQLSERVER MSSQL16.SQLSERVER 数据库引擎服务 1033 Developer Edition 16.0.1000.6 否 是
SQL Server 2022 SQLSERVER MSSQL16.SQLSERVER 数据库引擎服务 2052 Developer Edition 16.0.1000.6 否 是
SQL Server 2022 SQLSERVER MSSQL16.SQLSERVER SQL Server 复制 1033 Developer Edition 16.0.1000.6 否 是
SQL Server 2022 SQLSERVER MSSQL16.SQLSERVER SQL Server 复制 2052 Developer Edition 16.0.1000.6 否 是
SQL Server 2022 SQLSERVER MSSQL16.SQLSERVER 全文和语义提取搜索 1033 Developer Edition 16.0.1000.6 否 是
SQL Server 2022 SQLSERVER MSSQL16.SQLSERVER Data Quality Services 1033 Developer Edition 16.0.1000.6 否 是
SQL Server 2022 SQLSERVER MSSQL16.SQLSERVER Data Quality Services 2052 Developer Edition 16.0.1000.6 否 是
SQL Server 2022 SQLSERVER MSSQL16.SQLSERVER 机器学习服务和语言扩展 1033 Developer Edition 16.0.1000.6 否 是
SQL Server 2022 SQLSERVER MSAS16.SQLSERVER Analysis Services 1033 Developer Edition 16.0.1000.6 否 是
SQL Server 2022 SQLSERVER MSAS16.SQLSERVER Analysis Services 2052 Developer Edition 16.0.1000.6 否 是
SQL Server 2022 SQLEXPRESS MSSQL16.SQLEXPRESS 数据库引擎服务 1033 Express Edition 16.0.1000.6 否 是
SQL Server 2022 SQLEXPRESS MSSQL16.SQLEXPRESS 数据库引擎服务 2052 Express Edition 16.0.1000.6 否 是
SQL Server 2022 SQLEXPRESS MSSQL16.SQLEXPRESS SQL Server 复制 1033 Express Edition 16.0.1000.6 否 是
SQL Server 2022 SQLEXPRESS MSSQL16.SQLEXPRESS SQL Server 复制 2052 Express Edition 16.0.1000.6 否 是
SQL Server 2022 SQLEXPRESS MSSQL16.SQLEXPRESS 全文和语义提取搜索 1033 Express Edition 16.0.1000.6 否 是
SQL Server 2022 SQLEXPRESS MSSQL16.SQLEXPRESS 机器学习服务和语言扩展 1033 Express Edition 16.0.1000.6 否 是
SQL Server 2022 Data Quality Client 2052 Developer Edition 16.0.1000.6 否 是
SQL Server 2022 Integration Services 2052 Developer Edition 16.0.1000.6 否 是
SQL Server 2022 Scale Out 主要角色 2052 Developer Edition 16.0.1000.6 否 是
SQL Server 2022 Scale Out 辅助角色 2052 Developer Edition 16.0.1000.6 否 是
SQL Server 2022 LocalDB 2052 Express Edition 16.0.1000.6 否 是
SQL Server 2022 Master Data Services 2052 Developer Edition 16.0.1000.6 否 是
Package properties:
Description: Microsoft SQL Server 2022
ProductName: SQL Server 2022
Type: RTM
Version: 16
SPLevel: 0
Installation location: D:\SQL2022\Developer_CHS\x64\setup\
Installation edition: Developer
注意: 请阅读 aka.ms/useterms 上的 Microsoft SQL Server 软件许可条款。
用户输入设置:
ACTION: Repair
AGTDOMAINGROUP: <空>
AGTSVCACCOUNT: <空>
AGTSVCPASSWORD: <空>
AGTSVCSTARTUPTYPE: Manual
ASCONFIGDIR: Config
ASSVCACCOUNT: NT Service\MSSQLServerOLAPService
ASSVCPASSWORD: <空>
ASTELSVCACCT: NT Service\SSASTELEMETRY
ASTELSVCPASSWORD: <空>
ASTELSVCSTARTUPTYPE: Automatic
CONFIGURATIONFILE: C:\Program Files\Microsoft SQL Server\160\Setup Bootstrap\Log\20250422_223734\ConfigurationFile.ini
ENU: false
EXTSVCACCOUNT: NT Service\MSSQLLaunchpad
EXTSVCPASSWORD: <空>
FAILOVERCLUSTERGROUP: <空>
FAILOVERCLUSTERNETWORKNAME: <空>
FTSVCACCOUNT: NT Service\MSSQLFDLauncher
FTSVCPASSWORD: <空>
HELP: false
IACKNOWLEDGEENTCALLIMITS: false
INDICATEPROGRESS: false
INSTANCENAME: MSSQLSERVER
ISMASTERSVCACCOUNT: NT Service\SSISScaleOutMaster160
ISMASTERSVCPASSWORD: <空>
ISMASTERSVCPORT: 8391
ISMASTERSVCSSLCERTCN: <空>
ISMASTERSVCSTARTUPTYPE: Automatic
ISMASTERSVCTHUMBPRINT: F5F1C4E7D076BDA8504D3263E1DBF27ADD8D95D6
ISSVCACCOUNT: NT Service\MsDtsServer160
ISSVCPASSWORD: <空>
ISSVCSTARTUPTYPE: Automatic
ISTELSVCACCT: NT Service\SSISTELEMETRY160
ISTELSVCPASSWORD: <空>
ISTELSVCSTARTUPTYPE: Automatic
ISWORKERSVCACCOUNT: NT Service\SSISScaleOutWorker160
ISWORKERSVCCERT: <空>
ISWORKERSVCMASTER: <空>
ISWORKERSVCPASSWORD: <空>
ISWORKERSVCSTARTUPTYPE: Automatic
QUIET: false
QUIETSIMPLE: false
SQLSVCACCOUNT: NT Service\MSSQLSERVER
SQLSVCPASSWORD: <空>
SQLTELSVCACCT: NT Service\SQLTELEMETRY
SQLTELSVCPASSWORD: <空>
SQLTELSVCSTARTUPTYPE: Automatic
SUPPRESSPAIDEDITIONNOTICE: false
SUPPRESSPRIVACYSTATEMENTNOTICE: false
UIMODE: Normal
Configuration file: C:\Program Files\Microsoft SQL Server\160\Setup Bootstrap\Log\20250422_223734\ConfigurationFile.ini
Detailed results:
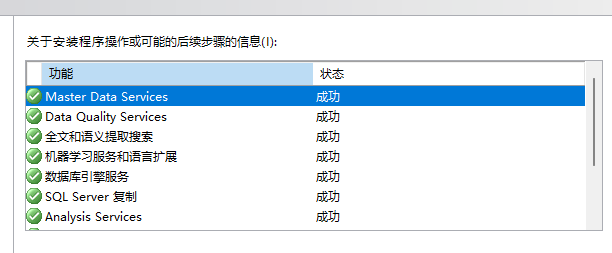
Feature: Master Data Services
Status: 已通过
Feature: Data Quality Services
Status: 失败
Reason for failure: 该功能的某个依赖项出错,导致该功能的安装过程失败。
Next Step: 使用以下信息解决错误,然后再次尝试运行安装过程。
Component name: SQL Server 数据库引擎服务实例功能
Component error code: 0x84B40002
Error description: SQL Server 功能“SQL_Engine_Core_Inst”所处的状态不支持修复,因为从未成功配置该功能。只能修复成功安装的功能。若要继续,请删除指定的 SQL Server 功能。
Error help link: https://go.microsoft.com/fwlink?LinkId=20476&ProdName=Microsoft+SQL+Server&EvtSrc=setup.rll&EvtID=50000&ProdVer=16.0.1000.6&EvtType=0x2841E06E%401204%402&EvtType=0x2841E06E%401204%402
Feature: 全文和语义提取搜索
Status: 失败
Reason for failure: 该功能的某个依赖项出错,导致该功能的安装过程失败。
Next Step: 使用以下信息解决错误,然后再次尝试运行安装过程。
Component name: SQL Server 数据库引擎服务实例功能
Component error code: 0x84B40002
Error description: SQL Server 功能“SQL_Engine_Core_Inst”所处的状态不支持修复,因为从未成功配置该功能。只能修复成功安装的功能。若要继续,请删除指定的 SQL Server 功能。
Error help link: https://go.microsoft.com/fwlink?LinkId=20476&ProdName=Microsoft+SQL+Server&EvtSrc=setup.rll&EvtID=50000&ProdVer=16.0.1000.6&EvtType=0x2841E06E%401204%402&EvtType=0x2841E06E%401204%402
Feature: 机器学习服务和语言扩展
Status: 失败
Reason for failure: 该功能的某个依赖项出错,导致该功能的安装过程失败。
Next Step: 使用以下信息解决错误,然后再次尝试运行安装过程。
Component name: SQL Server 数据库引擎服务实例功能
Component error code: 0x84B40002
Error description: SQL Server 功能“SQL_Engine_Core_Inst”所处的状态不支持修复,因为从未成功配置该功能。只能修复成功安装的功能。若要继续,请删除指定的 SQL Server 功能。
Error help link: https://go.microsoft.com/fwlink?LinkId=20476&ProdName=Microsoft+SQL+Server&EvtSrc=setup.rll&EvtID=50000&ProdVer=16.0.1000.6&EvtType=0x2841E06E%401204%402&EvtType=0x2841E06E%401204%402
Feature: 数据库引擎服务
Status: 失败
Reason for failure: 在此功能的安装过程中出错。
Next Step: 使用以下信息解决错误,然后再次尝试运行安装过程。
Component name: SQL Server 数据库引擎服务实例功能
Component error code: 0x84B40002
Error description: SQL Server 功能“SQL_Engine_Core_Inst”所处的状态不支持修复,因为从未成功配置该功能。只能修复成功安装的功能。若要继续,请删除指定的 SQL Server 功能。
Error help link: https://go.microsoft.com/fwlink?LinkId=20476&ProdName=Microsoft+SQL+Server&EvtSrc=setup.rll&EvtID=50000&ProdVer=16.0.1000.6&EvtType=0x2841E06E%401204%402&EvtType=0x2841E06E%401204%402
Feature: SQL Server 复制
Status: 失败
Reason for failure: 该功能的某个依赖项出错,导致该功能的安装过程失败。
Next Step: 使用以下信息解决错误,然后再次尝试运行安装过程。
Component name: SQL Server 数据库引擎服务实例功能
Component error code: 0x84B40002
Error description: SQL Server 功能“SQL_Engine_Core_Inst”所处的状态不支持修复,因为从未成功配置该功能。只能修复成功安装的功能。若要继续,请删除指定的 SQL Server 功能。
Error help link: https://go.microsoft.com/fwlink?LinkId=20476&ProdName=Microsoft+SQL+Server&EvtSrc=setup.rll&EvtID=50000&ProdVer=16.0.1000.6&EvtType=0x2841E06E%401204%402&EvtType=0x2841E06E%401204%402
Feature: Analysis Services
Status: 已通过
Feature: SQL Browser
Status: 已通过
Feature: SQL 编写器
Status: 已通过
Feature: LocalDB
Status: 已通过
Feature: Scale Out 辅助角色
Status: 已通过
Feature: Scale Out 主要角色
Status: 已通过
Feature: Integration Services
Status: 已通过
Feature: Data Quality Client
Status: 已通过
Feature: 安装程序支持文件
Status: 已通过
Rules with failures or warnings:
Rules report file: C:\Program Files\Microsoft SQL Server\160\Setup Bootstrap\Log\20250422_223734\SystemConfigurationCheck_Report.htm
可以看到关键的一行 Exit code (Decimal): -2068578302,对应的十六进制代码是0x84B30002,表示 SQL Server Setup has encountered an error while setting up the SQL Engine service.,也就是说 SQL Server 的核心组件(数据库引擎服务)在启动或修复时挂了。(没啥用)